Содержание
- Определение - Что означает Apache Kafka?
- Введение в Microsoft Azure и Microsoft Cloud | Из этого руководства вы узнаете, что такое облачные вычисления и как Microsoft Azure может помочь вам перенести и запустить свой бизнес из облака.
- Техопедия объясняет Апаче Кафку
Определение - Что означает Apache Kafka?
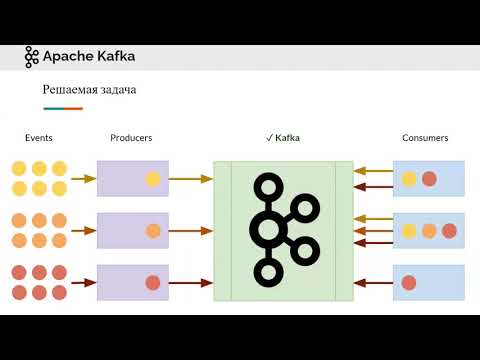
Apache Kafka - это система публикации-подписки с открытым исходным кодом, разработанная для обеспечения быстрой, масштабируемой и отказоустойчивой обработки потоков данных в реальном времени. В отличие от традиционного программного обеспечения для обмена корпоративными сообщениями, Kafka может обрабатывать все данные, проходящие через компанию, и делать это практически в реальном времени.
Kafka написан на Scala и изначально был разработан LinkedIn. С тех пор ряд компаний использовали его для создания платформ в реальном времени.
Введение в Microsoft Azure и Microsoft Cloud | Из этого руководства вы узнаете, что такое облачные вычисления и как Microsoft Azure может помочь вам перенести и запустить свой бизнес из облака.
Техопедия объясняет Апаче Кафку
Kafka имеет много общего с журналами транзакций, и она поддерживает каналы в темах. Производители записывают данные в разделы, а потребители - из этих разделов, которые распределяются и реплицируются по нескольким узлам в формате распределенной системы. Kafka уникален тем, что каждый раздел темы обрабатывается как журнал, и каждому разделу присваивается уникальное смещение. Он сохраняет все данные в течение определенного периода времени, и потребители несут ответственность за отслеживание своего местоположения в каждом журнале. Это отличается от предыдущих систем, где за это отслеживание отвечали брокеры, что сильно ограничивало возможность масштабирования систем по мере увеличения числа потребителей. Эта структура позволяет Kafka поддерживать множество потребителей и сохранять большие объемы данных с очень низкими издержками.
Кафка может быть использована:
- Как традиционный брокер
- Для отслеживания активности сайта
- Для агрегации журналов
- Для обработки больших потоков данных
Kafka может использоваться вместе с Apache Storm, Apache HBase и Apache Spark для анализа в реальном времени и рендеринга потоковых данных.